I’ve shipped enough mobile apps to know that success is won in onboarding, not in the demo.
Mobile App Onboarding: Key Findings
Mobile App Onboarding Overview
If you set the operating model, non‑functional requirements (NFRs), and measurement plan early on, you’ll reduce delivery risk, keep budgets real, and launch on time without compromising quality.
I’ll explain how to get it right.
Stop Your Mobile Project Going Sideways in Month One
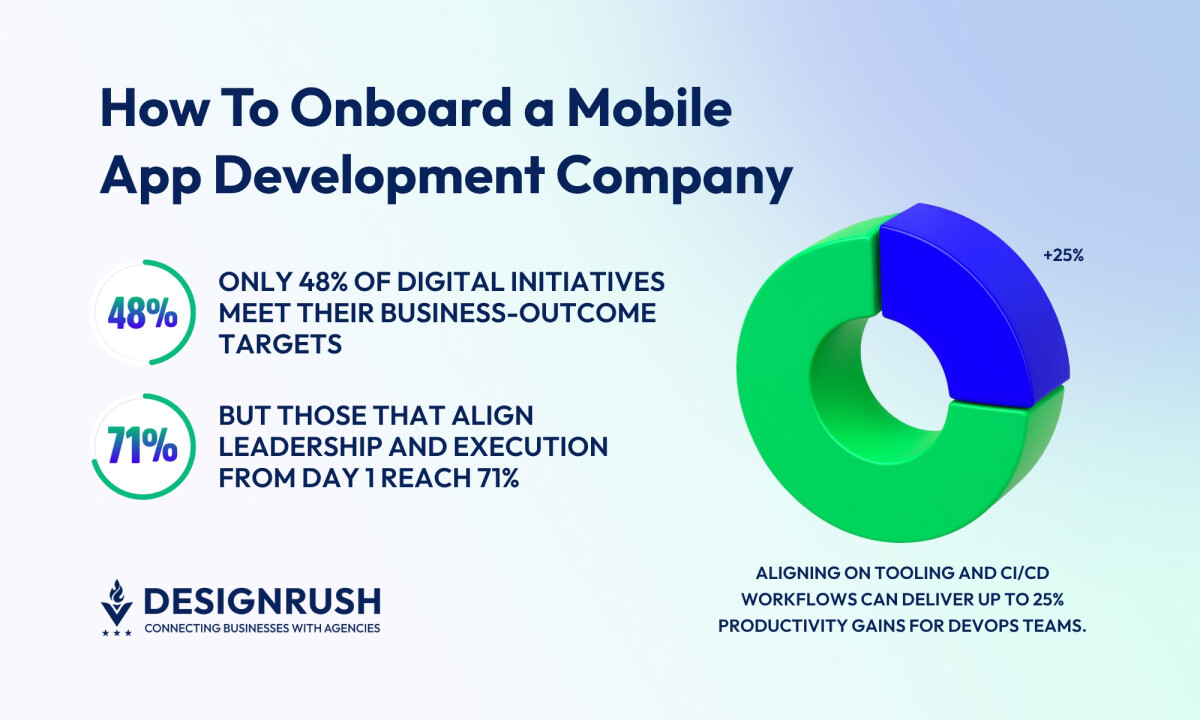
The reality is that only 48% of digital initiatives meet their business-outcome targets, but organizations that align leadership and execution from day one through clear goals, effective communication, and established decision-making processes are able to reach a 71% success rate.
Since my first years in this business, I’ve noticed that mobile projects wobble early in the app onboarding process because of five predictable, fixable issues. Below I spell out the exact fix for each and the inputs to gather before kickoff in order to align effectively.
That will make onboarding the agency fast, accountable, and measurable.
- Scope is vague, dates slip
- No early user testing of the first‑run flow
- Backend integration details show up late
- Post‑launch work is unfunded
- Feedback cycles are slow and approvals sprawl
1. Scope is Vague, Dates Slip
Early scope often reads like a shopping list with no acceptance criteria or NFR budgets. I’ve seen how that ambiguity guarantees rework and timeline drift.
For example: For a fintech startup, we saw scope creep due to vague feature lists without clear priorities or acceptance criteria. Narrowing the focus to key outcomes like “50% user activation in 60 days” helped avoid scope drift and set a realistic timeline.
Keith Shields, CEO and co-founder of Designli, reminds us to focus on your core value proposition and solving the problem your software is meant to solve.
“...map out the features that are absolutely necessary to deliver on that promise,” he says. “Everything else is a ‘nice to have’ and can be deferred to future iterations.”
Fix: Define a thin slice (small, testable feature) that proves the pipeline end-to-end. Tie scope to outcomes (activation, conversion, retention), and write crisp acceptance criteria and NFRs.
Inputs to acquire:
- First-draft MoSCoW list (Must/Should/Could/Won’t)
- Acceptance criteria for the thin slice (happy path + edge cases)
- NFR budgets (cold start, crash-free %, app size, accessibility targets)
- Timeline guardrails (milestones, demo cadence, cut criteria)
2. No Early User Testing of the First‑Run Flow
View this post on Instagram
Teams jump from wireframes to code without validating the onboarding mobile app journey (first run → permission prompts → paywall or first value).
You can expect to lose a large portion of new users in those first 90 seconds if there’s friction.
For example: I saw the result of skipping early user testing on a project — high drop-off due to onboarding confusion. After testing with a clickable prototype, we caught and fixed those issues before development, saving time later.
Fix: Test the onboarding path before build. Run five-to-seven user walkthroughs on a clickable prototype; ship version one with a progress indicator and one clear “first value” moment.
Inputs to acquire:
- Prototype of the first-run flow (clickable)
- Test plan and five-to-seven target users (screeners + consent)
- Definition of “first value” (what the user should achieve in one or two minutes)
- Analytics plan (events for drop-offs: screens, taps, permission prompts)
3. Backend Integration Details Show Up Late
I like to think of mobile as the UI for a company’s services. When API contracts, auth flows, rate limits, or schema changes are undefined, your critical path fills with blockers.
For example: This happened with an eCommerce app, where backend details like API contracts and authentication were finalized too late, causing delays. But we were able to ensure smooth integration during development by freezing these elements early.
Fix: Freeze a version-one API contract early, backed by a mock server. Agree auth, environments, rate limits, and a schema-change playbook.
Inputs to acquire:
- OpenAPI or GraphQL schema with example data
- Authentication method (OAuth, OpenID Connect, session) and rules for refreshing or expiring tokens
- Sandbox data and mock server URL, plus service-level agreements (SLAs) for availability and latency
- Versioning and change policy (who approves changes, notice period, and rollback plan)
4. Post‑Launch Work is Unfunded
Neglecting to budget for the likes of post-launch operating system (OS) updates and bug fixes could cause stress when issues arise. OS releases, software development kit (SDK) deprecations, and app‑store feedback loops are facts of life.
If you don’t reserve capacity, your roadmap suffers.
For example: I made this mistake once and an OS update causing crashes delayed our roadmap. Afterward, we allocated 20% for maintenance, ensuring smoother handling of issues.
Fix: Ring-fence a sustainment budget (e.g., 20–30% of capacity) and define a weekly triage for crashes, reviews, and OS/SDK changes.
Inputs to acquire:
- Reserve capacity and budget line for maintenance
- Release calendar (iOS/Android OS dates, SDK sunsets)
- Error budget and crash thresholds (SLOs)
- Escalation paths for store reviews and hotfixes
5. Feedback Cycles Are Slow and Approvals Sprawl
Slack threads multiply, decisions get fuzzy, and “design by committee” starts creeping in. That’s when velocity drops while rework rises.
For example: I saw this recently with a media app project. Slow feedback and excessive approvals delayed launches. However, introducing a clear approval process and a single decision-maker sped up the process dramatically.
Fix: Set a decision cadence and a lean approval path. Use a single source of truth (issue tracker), short demo cycles, and a responsible, accountable, consulted, and informed (RACI) document for sign-offs.
Inputs to acquire:
- Stakeholder & decision map (who approves releases; who owns budget)
- RACI for scope changes, design decisions, and release gates
- Weekly demo/acceptance ritual with time-boxed decisions
- Definition of Done (DoD) per story (QA, analytics, accessibility, perf)
The Six‑Block Onboarding Blueprint For Mobile
Timelines vary, so structure onboarding as six fast-moving blocks you can sequence, each producing a reusable artifact (not another meeting).
On a recent project we replaced status calls with tangible outputs like decision logs, API mocks, test checklists, rollout plans, and KPI dashboards. Months later another team reused them and shipped in a day, and the weekly sync shrank to a 15-minute Q&A.
Here’s how we approached it:
- Block 1: The Charter
- Block 2: Access and security (24‑hour rule)
- Block 3: Working habits that scale
- Block 4: Architecture and NFR budgets
- Block 5: Build and ship a thin slice
- Block 6: Evidence & Reporting
Block 1: The Charter
Objective: Align on outcomes, risk guardrails, and the first thin slice.
How I run it: A 60–90 minute kickoff, focusing on mobile app-specific decisions like the app’s core functionality, NFRs, and the first user experience flow.
For example: During a mobile eCommerce project, we defined the thin slice as "add to cart → checkout," aligning on metrics like conversion rate and cart abandonment.
Outcomes to aim for:
- One‑page success plan (three outcomes, two guardrails, one thin slice).
- RACI in plain English: who approves design, who green‑lights releases, who fixes access stalls.
In a 90-minute kickoff, we commit to something like “50% activation by month three,” set a crash-free guardrail, and pick a thin slice: “sign in → first value.”
Block 2: Access & Security (24‑hour rule)
Objective: Make credentials and environments a non‑event.
How I run it: Provision least-privilege access to code repositories, Apple/Google developer consoles, crash analytics tools (e.g., Firebase, Crashlytics), and feature flag systems (e.g., LaunchDarkly).
On day one, everyone should have access to GitHub, continuous integration and continuous delivery/deployment (CI/CD) systems, and the app store consoles for both iOS and Android.
For example: If there’s a serious issue with the app late on a Friday, the person on call can quickly fix it using an emergency “break glass” procedure, without needing to wait for approval.
Outcomes to aim for:
- Access roster with owners and expiry dates.
- Signed policies for secrets, signing keys, and offboarding.
Block 3: Working Habits That Scale
Objective: Reduce coordination tax without starving decisions.
How I run it: Replace endless Slack threads with a structured weekly steering session. We focus on critical issues like app performance (e.g., cold start times) and UI feedback.
For example: After a sprint demo for a fitness app, the team reviews key metrics like app size, crash-free percentage, and time to first value (TTFV).
Outcomes to aim for:
- Meeting rhythm + risks, assumptions, issues, and dependencies (RAID) log.
- Definition of Ready/Done pinned in the repo.
We replace sprawling Slack threads with a weekly 30-min steering doc and a RAID log. Instead of “who said what?” it’s “here’s the owner and due date.”
Block 4: Architecture & NFR Budgets
Objective: Prevent future “performance debt” by budgeting non‑functionals now.
How I run it: Establish mobile-specific performance, reliability, security, and accessibility budgets.
For example: For a media streaming app, we set crash-free sessions at 99.5%, with a target of 99.8% by the end of month three. We also set an app size ceiling of 50 MB and a cold start time target of <1.5 seconds for Android and less than one second for iOS devices.
Outcomes to aim for:
- Cold start P50 ≤ 1.8s (Android mid‑tier), ≤ 1.2s (recent iPhones).
- Crash‑free sessions ≥ 99.5% (target 99.8% by month three).
- App size ceiling: ≤ 50 MB initial download.
- Application not responding (ANR) rate ≤ 0.3% of sessions; store guideline checklist per build.
Our CI gates hard-startup time and bundle size. A PR that adds +18 MB gets auto-rejected, and the team refactors before any user feels the drag.
Block 5: Build & Ship a Thin Slice
Objective: Prove the pipeline, not the pitch deck.
How I run it: Ship a small, fully functional feature behind a feature flag.
For example: We launched the "in-app purchase" feature of an eCommerce app to test the user flow in real conditions without exposing it to all users.
This thin slice allowed us to monitor activation, time to first value (TTFV), and ensure proper integration with payment gateways.
Outcomes to aim for:
- Release notes, rollout plan, rollback runbook.
- Event instrumentation for activation and TTFV.
There's no denying the merit to proving the pipeline end-to-end before scaling the feature set. I’ve seen how bady it can go when you don’t.
Block 6: Evidence & Reporting
Objective: Make week one measurable; keep leaders focused on signals, not adjectives.
How I run it: Publish a 60-second executive dashboard showing app-specific metrics like activation rate, crash-free percentage, ANR rate, and TTFV.
For example: For a recent health app, we tracked key metrics like user registration, app session length, and in-app purchases in real-time. This allowed us to quickly pivot or scale based on data.
Outcomes to aim for:
- Single dashboard URL in every status doc.
- Alerts tuned to thresholds, not noise.
The Monday review shifts from opinions to “what experiment do we run next?” But if status isn’t visible in 60 seconds, I've found you can easily slip into managing by vibes.
CI/CD & Test Lab: A Zero‑Friction Recipe for Mobile
If you want to prevent rework, unblock developers, and save weeks across build, test, and release, my advice is to set up CI/CD, secure access, build lanes, device testing, and observability on day one.
1. Identity and Access
Immediately provision the full toolchain, enforcing least-privilege roles and strong authentication.
- Enforce SSO + MFA across all systems.
- Assign least-privilege roles and name an owner for each resource.
- Provision access to code host, issue tracker, CI/CD, artifact registry, analytics, crash reporting, feature flags, remote config, and store consoles.
- Define offboarding and break-glass procedures with auditable logs.
Day-one check: Zero “blocked on access” messages; all access requests handled within 4 hours.
2. Build Lanes
Separate pipelines per platform and automate from PR to internal distribution.
- Keep signing keys in secure storage; never keep them in the code repository.
- Cache dependencies and run builds in parallel to keep PR feedback under 10 minutes.
- Automatically label artifacts with the commit, build number, and environment.
Day-one check: PRs get a green/red signal in ≤10 min; new build available to testers in ≤30 min.
3. Testing
Test on real, diverse hardware and route feedback through staged beta rings, progressively larger tester groups used to surface issues safely before full rollout.
- Maintain a device matrix (include low-memory Android and one-generation-old iPhones).
- Route feedback through beta rings: internal (engineering) → alpha (friendly customers) → external (geo-fenced/open).
- Cover the first-run journey (permissions, paywall/first value), offline/poor network, and accessibility in test plans.
- Stand up a hotfix lane with fast-track submission.
Day-one check: Smoke tests cover first-run; crash triage in 24 hours; hotfix path documented.
4. Observability
Put the core health and speed signals in one place and alert only on thresholds.
- Put crash-free %, ANR rate, cold start, TTFV, API error rate on one dashboard.
- Alert on thresholds/SLOs (not flapping): e.g., crash-free <99.5%, ANR >0.47%, cold start >p95 target, API error >1%.
- Add a 60-second exec view (trend + red/green state) and link to runbooks.
Day-one check: Dashboard live and shared; alerts route to an on-call with clear ownership.
5. Onboarding Choices, Business Results

A 2023 Forrester Consulting study found teams reported 10–25% dev-productivity gains and shipped 1–1.5 months sooner after adopting modern tools and cloud-based services that align development and operations for mobile app creation and maintenance.
We saw it play out in our last rollout, where setting feature flags, a typed API client, and an observability stack in week one kept crash-free sessions above 99.7% and pulled the thin-slice ship date forward by three weeks.
Contract Patterns That Protect Budget (and Relationships)
I structure contracts to protect budget and relationships so incentives stay aligned, scope stays honest, and delivery stays predictable. Clear outcomes, NFR budgets, and evidence-based milestones curb scope creep, reduce rework, and surface risks early.
- Focus on outcomes in the contract: For example, set clear goals like “Achieve 50% user activation by Month 3 and maintain 99.5% crash-free sessions.” While specific features can change, these goals and limits should stay fixed.
- Clearly define what "Done" means: Accept work only if agreed standards are met, like ensuring the app’s size is under 15 MB or that it loads within a set time. If not, the work isn’t complete.
- Plan for changes: Smaller changes are handled weekly. Bigger changes require a quick review (within 60 minutes), where the team decides whether to cut features, adjust pricing, or move deadlines, and then clearly documents the impact.
- Pay based on actual progress: Payments are tied to real deliverables, like when a part of the app is ready for testing (e.g., activation funnel set up, app crash-free for a full week).
- Knowledge transfer is part of the deal: Ensure that documentation like how-to guides, deployment instructions, and key checklists are created and shared with the team. This minimizes risk and keeps everything running smoothly.
Decision Rhythm: Minimal Meetings, Maximum Decisions
I’ve found that the best way to protect build time is a lightweight, predictable cadence that results in decisions and artifacts.
This rhythm cuts coordination tax, surfaces risks early, and gives leaders clear signals without derailing the team.
- Weekly Steering (30 min): Focus on key goals, risks, and decisions for the week ahead. This helps keep the team aligned on what’s next.
- Sprint demo (20-30 min): Show the progress of the software and share the latest updates, so everyone can see what’s been built.
- Retro (team-level): At the end of each sprint, the team identifies two ways to improve efficiency, such as fixing unreliable tests or speeding up builds.
- Work intake: Use a simple template to define problems, the value the solution brings, the requirements, and any technical impacts.
- RAID log: Review this weekly to address any unresolved issues, either closing them or escalating them for quick action.
Mobile App Onboarding: Final Words
I think of onboarding as the team’s operating system: the defaults you codify now will compound (good or bad). Favor reversible choices, make artifacts portable across teams, and put shared metrics where engineering, product, finance, and support see the same truth.
That alignment preserves momentum through roadmap churn, reorgs, and new hires.
Find More Agency Hiring Resources:
- Important Questions To Ask a Mobile App Development Agency
- Building a Practical Budget for Mobile App Development
- In-House vs. Web Development Agency
From build costs to hosting, tools, and long-term maintenance, the smartest teams fund outcomes that tie directly to KPIs. Do that, and your budget becomes a growth engine instead of a cost center.
![]()
Our team ranks agencies worldwide to help you find a qualified partner. Visit our Agency Directory for mobile app development companies:
- Top Software Development Companies
- Top Android App Development Companies
- Top iPhone App Development Companies
- Top Offshore Software Development Companies
- Top AI App Development Companies
Our development experts also spotlight the most groundbreaking app projects from around the world. Visit our Awards section to explore the best in app development.
Mobile App Onboarding FAQs
1. How do I keep the team from prioritizing speed over outcomes?
Give one north‑star outcome with two guardrails (e.g., activation ↑ while crash‑free ≥ 99.5% and app size ≤ 50 MB). If a shortcut violates a guardrail, require a written exception with a rollback plan.
2. What’s the right release tempo for mobile?
Weekly/bi‑weekly to beta; 2–4 weeks to production once stability is proven. Use staged rollouts and feature flags to de‑risk.







