Lost business, downtime, and recovery now outweigh breach response costs. In practice, underfunding cybersecurity saves little and often costs far more.
I break down what cybersecurity costs in 2026 and how to budget strategically to reduce risk.
Cybersecurity Costs: Key Findings
- Allocate 8–15% of IT budgets to cybersecurity; breaches cost $4.4–$4.9M globally and ~$10.2M in the U.S.
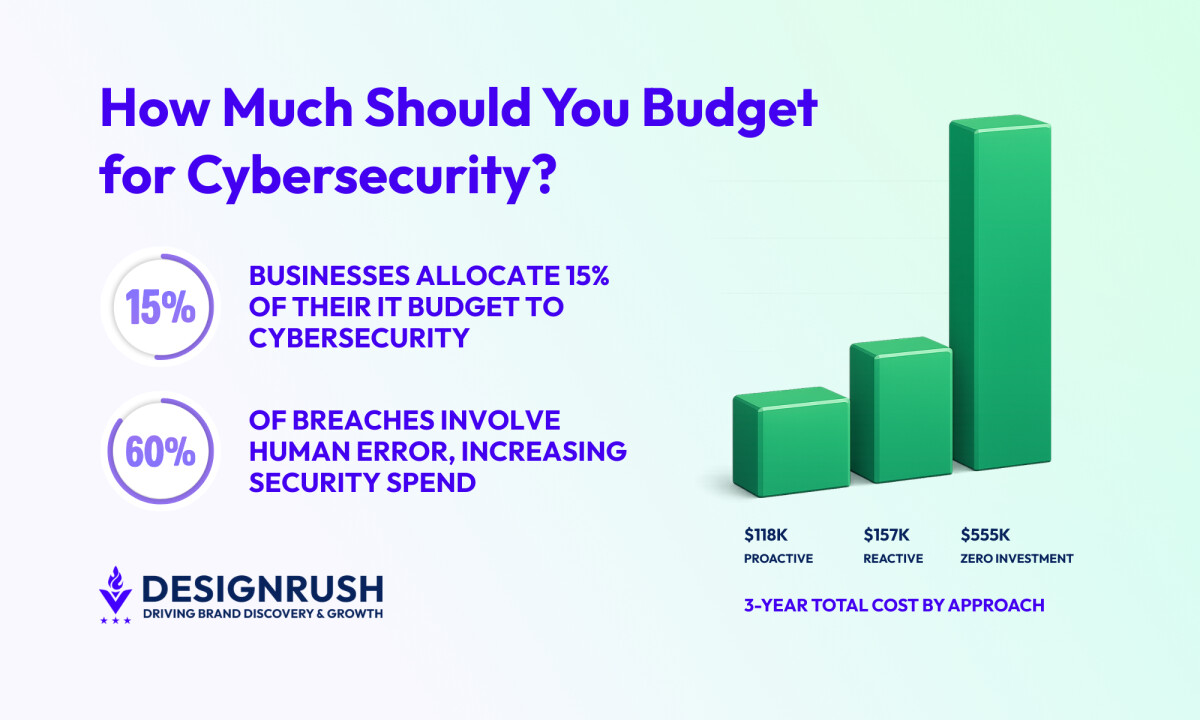
- Invest proactively; ~$118K over three years prevents repeated incidents that cost ~$555K when ignored.
- Outsource MDR for 24/7 coverage; managed services cost $25K–$50K per project vs. $155K–$239K per analyst in-house.
What Is the Average Cost of Cybersecurity?
Globally, businesses allocate about 13.2% of their IT budget to cybersecurity.
That often translates to roughly $8,000–$80,000 annually for small organizations, $100,000–$500,000 for mid-sized companies, and millions per year for large, regulated enterprises.
Why Budget for Cybersecurity?
I’ve spent decades helping companies budget for cybersecurity, and the data is clear: under-investing costs far more than proactive spending.
IBM’s 2024–2025 Cost of a Data Breach report puts the global average breach between $4.4 and $4.9 million, with U.S. organizations hit hardest at a record ~$10.2 million.
Even for small companies, a single incident commonly costs $120,000, and can exceed $4 million for larger or regulated businesses.
The consequences include:
- Business interruptions
- Revenue loss and downtime
- Lost customer and partner trust
- Brand reputation damage
- Regulatory fines and litigation
Every dollar spent on security should be judged against the losses it prevents.
From my experience, organizations with mature controls and tested incident response plans consistently contain incidents faster and at far lower total cost.
What Cybersecurity Spending Actually Covers
A well-rounded cybersecurity budget pays for prevention, detection, and survivability.
Here’s how that money should be spent when done correctly:
- Foundational security: Non-negotiables I never skip
- Managed detection and response (MDR)
- Governance, risk, and compliance
- Human risk management
- Security tools and technology
1. Foundational Security: Non-Negotiables I Never Skip
Every organization needs a baseline security foundation. This is where your budget should go before you even consider advanced tooling.
In practice, foundational spending covers:
- Network and endpoint protection: Firewalls, endpoint detection and response (EDR), anti-malware, and network segmentation
- Identity and access management (IAM): MFA everywhere it matters, strict privileged access controls, and removal of standing admin rights
- System hardening and patching: Vulnerability scanning plus timely patch orchestration
- Email and web security: Phishing filters, secure gateways, and domain protections.
- Logging and monitoring infrastructure: Centralized logs and SIEM readiness.
- Data/encrypted backups with immutability and restore testing
I’ve cut six-figure tool spend to fix patching, logging coverage, and access hygiene and reduced real risk more than any advanced tool.
2. Managed Detection & Response (MDR)
You can’t monitor security 24/7 with internal staff alone. MDR covers around-the-clock monitoring and incident detection.
Your MDR spend pays for:
- 24/7 analyst coverage
- Continuous log analysis and threat hunting
- Credential exposure monitoring on dark web markets
- Automated containment and response tools
When I evaluate MDR providers, I look at response guarantees: alert triage within minutes (often <15 min for critical alerts) and containment within an hour.
3. Governance, Risk, and Compliance
This budget line covers:
- Risk assessments and security reviews
- Policy creation and enforcement
- Ongoing compliance evidence collection
- Audit preparation and remediation tracking
The companies that suffer least during audits are the ones that collect evidence continuously.
I also tell clients to plan a compliance contingency for when insurance or regulations change.
4. Human Risk Management
People are part of the system. Most studies show that 60% of breaches involve a human element, whether through error, privilege misuse, stolen credentials, or social engineering.
That tracks exactly with what I see in incident reviews: phishing, credential reuse, misconfigurations, and insider negligence.
Human risk spending includes:
- Security awareness training
- Realistic phishing simulations with follow-up coaching
- Background checks (pre- and post-employment)
- Device and access management for remote staff
Don’t overlook the potential cost of negligent or malicious insiders: these can cause breaches or data leaks that insurance may not fully cover.
5. Security Tools & Technology
Finally, budgets include specialized tools and automation. In practice, funds here go to license fees and implementation.
Tool budgets cover:
- SIEM/SOAR platforms
- UEBA analytics
- Threat intelligence subscriptions
- Vulnerability scanners
- Penetration tests
- AI-assisted tools
Modern budgets also invest in automation.
IBM found organizations that use AI/automation in security saved roughly $1.9M on average per breach and cut detection and containment time by ~100 days.
What Factors Determine the Cost of Cybersecurity?
In my experience, several key factors drive how much organizations end up spending on security:
- Team model: In-house vs. agency
- Organization and workforce size
- Existing security maturity and technical debt
- Volume and sensitivity of data
- Industry-specific risk profiles
1. Team Model: In-House vs. Agency
The single biggest cost lever is how you staff detection and response.
In-House
An in-house SOC is expensive because labor dominates the cost, which scales directly with headcount.
For instance, a functional 24/7 SOC requires:
- 8–10 full-time analysts just to cover shifts, time off, and attrition
- Senior staff for escalation and incident command
- Continuous training to prevent skill decay
And this doesn’t account for the cost drivers I see repeatedly:
- Talent scarcity: Senior analysts are hard to hire and harder to keep
- Compensation and benefits: Senior cybersecurity analysts earn $155K–$239K/yr, plus benefits
- Coverage gaps: Nights, weekends, and holidays reduce response quality
- Poor scalability: Headcount does not scale during alert spikes or incidents
Annual training costs alone illustrate the burden. Security Magazine 2025 reports average annual security training spend:
Industry | Average Annual Spend |
Banking & Insurance | $250,000 |
Healthcare | $637,000 |
Manufacturing | $371,000 |
Government / IT / Media | $46,000 |
Agencies
Outsourcing flips the cost model: you pay for coverage and access to specialized expertise, not headcount. It runs on subscription or hourly rates ranging from $50-$200 per hour.
It converts variable labor costs into a predictable budget line. In my experience, this typically yields better ROI if you lack the scale to hire and retain full security teams.
As Ivan Dabic, Co-Founder and CEO of BlueGrid, puts it:
“Think of it as outsourcing your security team to experts who eat, sleep, and breathe cybersecurity.
With SOC as a Service, you get access to top-tier security expertise without the overhead of hiring, training, and retaining an in-house team.”
Typical costs by business size:
Business Size | Average per Hour | Minimum Budget |
Small business/startup | $50-$100/hr | $10,000-$25,000 |
Mid-size business | $100-$200/hr | $25,000-$50,000 |
Enterprise | $200+/hr | $50,000+ |
Real-world project examples I’ve seen:
- $100K – $250K → OT cybersecurity web platform (12 months) by Origami Studios
- $500K – $1M → Hubspot platform modernization with security features (24 months) by Digis agency
Outsourcing reduces headcount burden, provides coverage 24/7, and gives access to expertise you likely can’t hire internally, while keeping costs predictable.
2. Organization and Workforce Size
Headcount drives many license and service costs.
Around 50–200 employees, companies typically must add 24/7 monitoring, mature vulnerability management, and begin formal IAM.
Beyond ~500 employees, formal security governance becomes mandatory.
Observed thresholds and spend (Total Assure data):
Business Size (Employees) | Average Annual Cybersecurity Spend | IT Budget Allocation | Key Cost Driver |
1–10 | ~$8,500 | 5–15% | Higher per-employee costs due to fixed security infrastructure |
11–50 | ~$25,400 | 8–18% | Best economies of scale for security investment |
51–100 | ~$78,000 | 10–20% | Increased complexity and regulatory exposure |
3. Existing Security Maturity and Technical Debt
Weak security baselines drive the highest long-term costs. Unpatched systems, flat networks, and unmanaged secrets create technical debt that compounds over time.
Skipping investment is not cheap: a single breach averages $180–$185K.
Cost comparison (Total Assure data):
Cybersecurity Approach | Annual Spend | Cost per Incident | 3-Year Total Cost | Notes |
Zero Investment | $0 | ~$185,000 | ~$555,000 | Cheapest upfront, most expensive long-term |
Reactive | ~$18,500 | ~$87,000 | ~$157,200 | Lower upfront, high incident costs |
Hybrid | ~$27,200 | ~$45,000 | ~$126,600 | Moderate spend and risk reduction |
Proactive | ~$34,800 | ~$28,000 | ~$118,400 | Highest upfront, lowest total cost |
In practice, a one-time remediation of legacy gaps is often more cost-effective than paying for multiple small-breach responses.
4. Volume and Sensitivity of Data
The amount and sensitivity of data you handle directly inflate costs. Breaches exposing regulated PII/PHI carry mandatory fines and legal exposure.
IBM quantifies this above: the cost per record jumps when sensitive data is lost. By contrast, breaches of non-sensitive data are cheaper to remediate.
Cost factors tied to data:
- Volume: More records require larger storage, monitoring, and backup capacity
- Sensitivity: Sensitive or regulated data requires encryption, DLP, and audit-ready controls
- IT complexity: Multiple cloud platforms, on-prem systems, and critical applications increase monitoring and integration costs
- Operational criticality: Streaming services or e-commerce platforms require near-zero downtime, driving higher investment in redundancy, detection, and response
5. Industry-Specific Risk Profiles
Some sectors underwrite a compliance premium. For example, healthcare, despite relatively older systems, outspends almost everyone due to HIPAA and the high value of patient data.
Averaging $7.42M per incident, healthcare breaches remain the most expensive. In response, the industry spent $125B cumulatively from 2020–2025 on cyber defenses alone.
Industry spend comparison and drivers (Total Assure data):
Industry | Annual Cybersecurity Spend | Compliance Premium | Typical Budget Mix | Additional Cost Factors |
Healthcare | $35,000 – $120,000 | +45% (HIPAA) | Heavily managed services | High data sensitivity and regulatory oversight |
Financial Services | $42,000 – $150,000 | +38% (SOX, PCI DSS) | Managed services + software | Transaction volume and fraud risk |
Manufacturing | $28,000 – $85,000 | +25% (NIST, CMMC) | Mixed approach | Added OT (operational technology) security costs |
Professional Services | $22,000 – $65,000 | +15% (SOC 2) | Software-heavy | Client confidentiality and trust requirements |
The bottom line: budget according to your vertical’s benchmarks.
Hidden Cybersecurity Costs Often Overlooked
From decades of responding to incidents and advising clients, I can tell you: the line-item security spend is only part of the cost.
Breaches create hidden expenses that often dwarf IT budgets.
- Downtime: I’ve seen organizations take months to contain incidents. IBM reports an average of 241 days in the global average breach lifecycle; even a few days offline can cost $15K/day or more.
- Lost opportunities: Breach response always diverts teams from high-value work. I’ve seen product launches delayed and marketing campaigns paused.
- Regulatory follow-up: Cross-border audits, data subject requests, and lawsuits extend costs well beyond the breach itself.
- Reputation: In B2B, trust recovery takes 2–6 quarters. Lost trust translates directly into lost revenue.
- Insurance ripples: Post-breach, insurers often demand policy upgrades or emergency security spend, doubling costs.
Best Practices for Smart Cybersecurity Budgeting
I’ve managed cybersecurity budgets for startups and enterprises, and the difference between waste and ROI comes down to structure, priorities, and executive alignment.
- Prioritize proactive investment: Companies that invest earlier tend to spend less over time than crisis spending.
- Assess current state and future risk exposure: Know your critical assets, regulatory exposure, and potential worst-case scenarios.
- Progressively build out: Start with basics: identity, patching, endpoints, backups, logging. As maturity grows, layer in 24/7 monitoring, audit pipelines, and automation to reduce toil.
- Continually optimize costs: Negotiate discounts, retire unused licenses, and shift low-value spend to smarter alert triage or AI-driven MDR.
- Plan for growth and change: Factor in headcount expansion, new technologies, cloud adoption, and changing compliance requirements.
- Build an exit and flexibility strategy: Ensure contracts, subscriptions, and tools can scale, pivot, or be offboarded without wasted spend.
Cybersecurity Budgeting: Final Words
The most effective investments are cross-functional: good log management, a trained incident response team, and ongoing security awareness. They shorten breach response and protect revenue.
Find More Agency Hiring Resources:
- SEO Budget: In-House vs. Agency
- Branding Costs: In-House vs. Agency
- In-House Marketing vs. Agency: Key Pros and Cons
![]()
Our team ranks agencies worldwide to help you find a qualified partner to implement the latest cybersecurity solutions. Visit our Agency Directory for the Top Cybersecurity Companies as well as:
- Top AI Cybersecurity Companies
- Top Digital Forensics Companies
- Top Identity Access Management Companies
- Top Penetration Testing Companies
- Top Security Assessment Companies
Cybersecurity Spending FAQs
1. How much should my business spend on cybersecurity?
Most companies allocate 8–15% of their IT budgets. Your exact budget depends on size, industry, and risk exposure, but proactive investment usually costs less than reacting to breaches.
2. Why invest in cybersecurity if nothing has gone wrong?
Cybersecurity is insurance against catastrophic losses. Spending covers identity controls, monitoring, backups, training, and incident response.
Companies with mature defenses recover faster, face fewer fines, and reduce downtime, making every dollar spent a safeguard against far higher costs.
3. Should we hire in-house oroutsource cybersecurity?
Outsourcing often delivers better protection at lower cost. Running a 24/7 in-house SOC is expensive and hard to scale.
Outsourced teams provide round-the-clock coverage, specialized expertise, and predictable pricing, ideal for small to mid-sized businesses.







